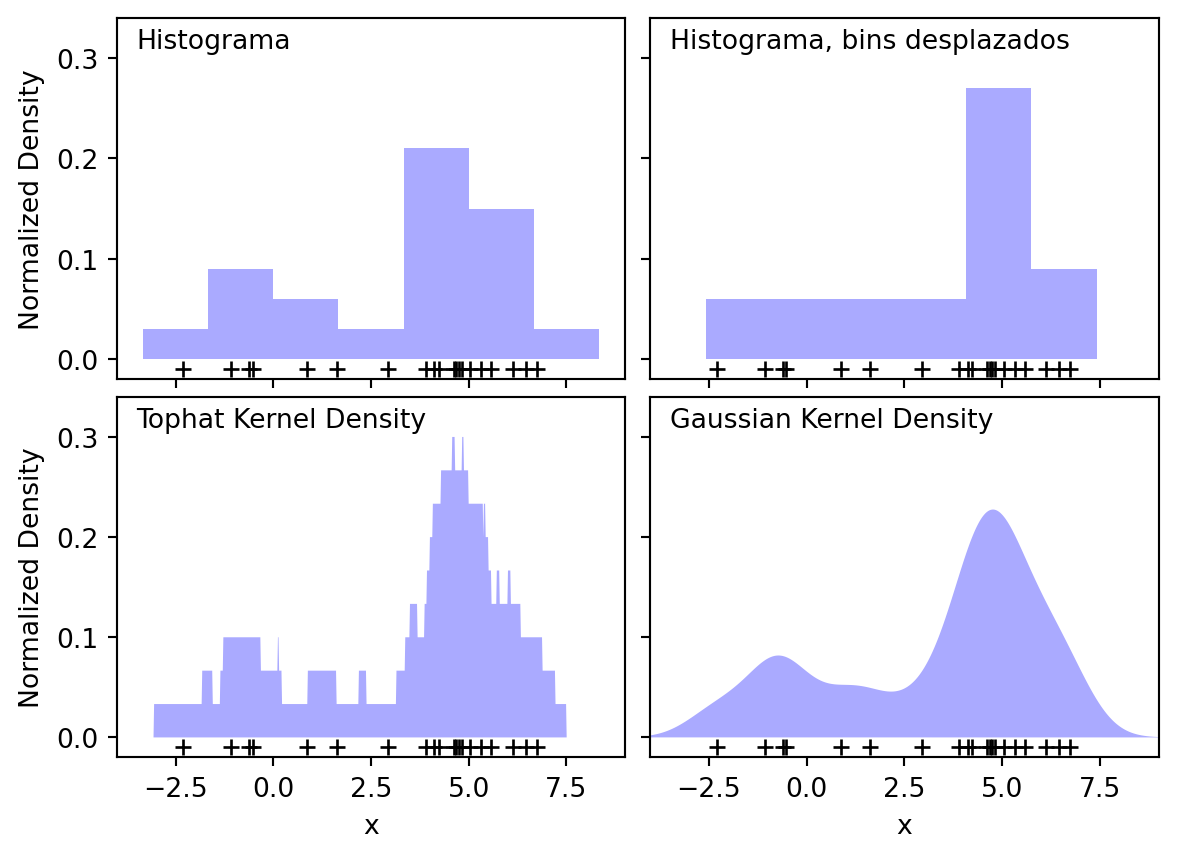
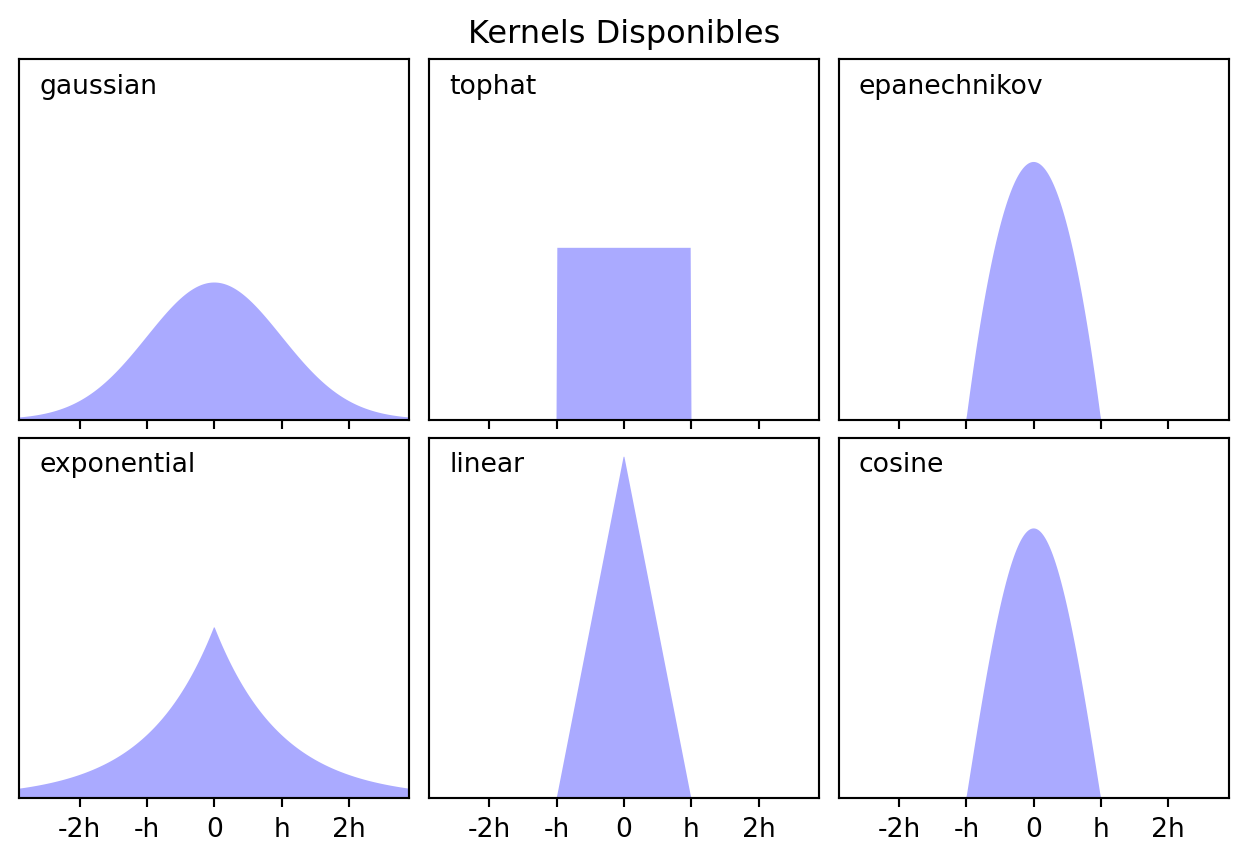
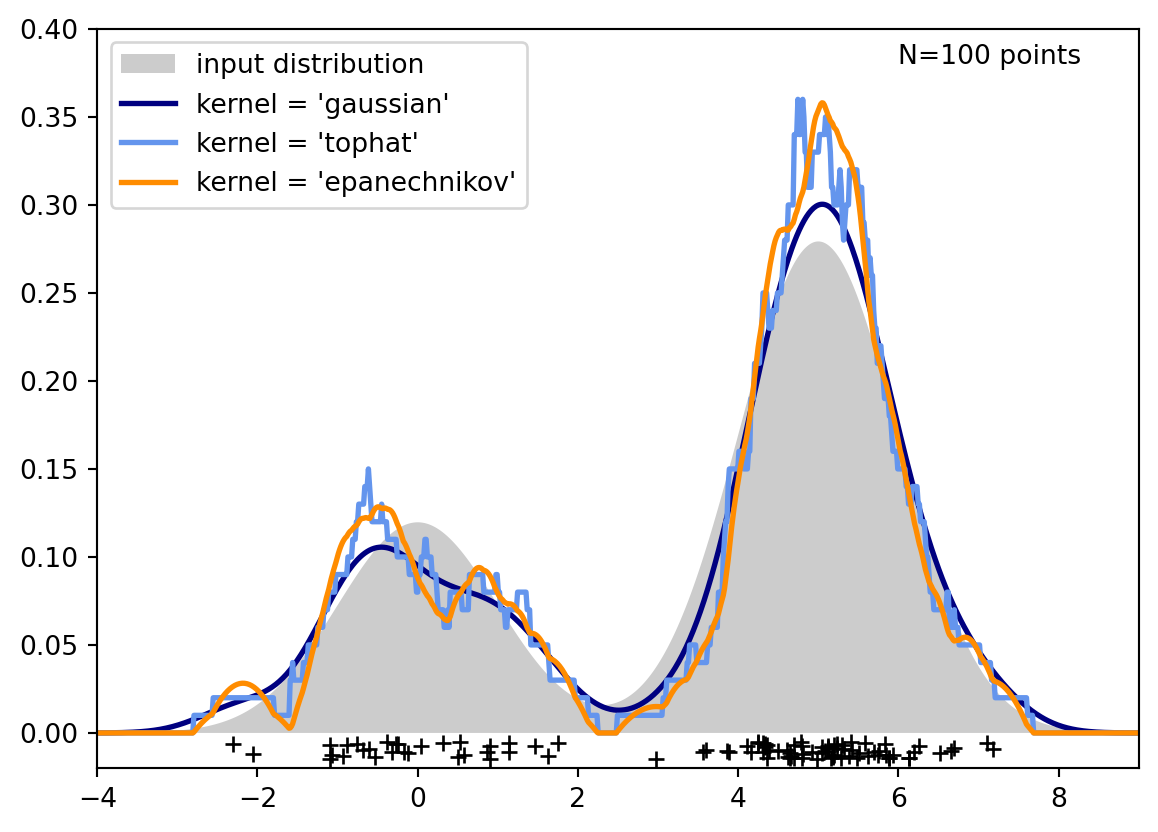
La estimación de la densidad es un problema de modelar la función de densidad (pdf) de la distribución desconcida del dataset. Sus aplicaciones principales son en la ditección de novedades e intrusiones. Anteriormente se trabajó con la estimación de la pdf para el caso paramétrico con la distribución normal multivariada. Acá usaremos el método del kernel, ya que este es no paramétrico.
Así, sea \(\{x_i\}_{i=1}^{N}\) un dataset de una dimensión donde las muestras son construidas a partir de una pdf desconocida \(f\) con \(x_i\in\mathbb{R}, \ \forall i=1, \ldots, N\). Estamos interesados en modelar la curva de la función \(f\). Con nuestro modelo de kernel, denotado por \(\hat{f}\), defindo como: \[
\hat{f}_h(x) = \dfrac{1}{Nh}\sum_{i=1}^{N} k\left(\dfrac{x-x_i}{h}\right)
\tag{9.1}\]
Donde \(h\) es un hiperparámetro que controla la relación sesgo-varianza. Acá usaremos el kernel gaussiano: \[\begin{equation}
k(z) = \dfrac{1}{\sqrt{2\pi}}\exp\left(\dfrac{-z^2}{2}\right)
\end{equation}\] Nosotros buscamos el valor de \(h\) que minimiza la diferencia entre la curva original \(f\) y la curva aproximada de nuestro modelo \(f_{h}\). Una medida razonable para esta diferencia es el error cuadrático medio integrado (MISE, por sus siglas en inglés), definido por: \[
MISE(b) = \mathbb{E}\left[\int_{\mathbb{R}}\left(\hat{f}_{h}(x)-f(x)\right)^2dx\right]
\tag{9.2}\]
En la ecuación (Ecuación 9.2) la integral \(\int_{\mathbb{R}}\) remplaza a la sumatoria \(\displaystyle\sum_{i=1}^{N}\) que empleamos en el promedio, mientras que la esperanza \(\mathbb{E}\) reemplaza el promedio \(\dfrac{1}{N}\).
Notese que cuando la función de pérdida es continua como la función de \(\left(\hat{f}_{h}(x)-f(x)\right)^2\), se reemplaza la sumatoria por la integrasl. El operador de esperanza \(\mathbb{E}\) siginifica que queremos que \(h\) sea el óptimo para todos las posibilidades del set de entrenamiento. Esto es importante debido a que \(\hat{f}_{h}\) es definido en un conjunto finito de datos de alguna distribución de probabilidad; mientras que la pdf real \(f\) está definida en un dominio infinito \(\mathbb{R}\).
Note que, reescribiendo el lado derecho de la (Ecuación 9.2), obtenemos \[\begin{equation*}
\mathbb{E}\left[\int_{\mathbb{R}}\hat{f}_{h}^{2}(x)dx\right]
-2\mathbb{E}\left[\int_{\mathbb{R}}\hat{f}_{h}(x)f(x)dx\right]
+ \mathbb{E}\left[\int_{\mathbb{R}}f^{2}(x)dx\right]
\end{equation*}\]
Note que el tercer término es independiente de \(h\) y podría ser ignorado. Un estimador insesgado del primer término está dado por \(\int_{\mathbb{R}}\hat{f}_{b}^{2}(x)dx\), mientras que el estimador insesgado para el segundo término está aproximado por \(\dfrac{-2}{N}\displaystyle\sum_{i=1}^{N}\hat{f}_{h}^{(i)}(x_i)\), donde \(\hat{f}_{h}^{(i)}(x_i)\) es el kernel con los datos de entrenamiento menos el dato \(x_i\).
El término \(\displaystyle\sum_{i=1}^{N}\hat{f}_{h}^{(i)}(x_i)\) es conocindo como el estimador de dejar una estimación por fuera (leave one out estimate); es una forma de validación cruzada donde cada fold contienen una muestra. Además, se puede ver como \(\int_{\mathbb{R}}\hat{f}_{h}(x)f(x)dx\) es la esperanza de la función \(\hat{f}_{h}\), esto por que \(f\) es una función de densidad. Se puede demostra que el estimador leave one out estimate es un estimador insesgado para \(\mathbb{E}\left[\int_{\mathbb{R}}\hat{f}_{h}(x)f(x)dx\right]\).
Ahora, para hallar el valor óptimo \(h^*\) para \(h\), queremos minimizar la función de costo definida por: \[
\displaystyle\int_{\mathbb{R}}\hat{f}*{h}^{2}(x)dx - \dfrac{2}{N}\displaystyle\sum*{i=1}^{N}\hat{f}_{h}^{(i)}(x_i)
\]
Se puede hallar \(h^*\) utilizando grid search¨. Para \(D\) dimensiones, el término del error \(x-x_i\) de la (Ecuación 9.1) puede ser reemplazado por la norma euclidea \(||\mathbb{x}-\mathbb{x}_{i}||\).
La agrupación es un problema de aprender a asignar una etiqueta a ejemplos aprovechando un no etiquetado conjunto de datos. Debido a que el conjunto de datos no está etiquetado en absoluto, decidir si el modelo aprendido es óptimo es mucho más complicado que en el aprendizaje supervisado. Existe una variedad de algoritmos de agrupamiento y, desafortunadamente, es difícil saber cuál es el mejor calidad para su conjunto de datos. Generalmente, el rendimiento de cada algoritmo depende de las propiedades desconocidas de la distribución de probabilidad de la que se extrajo el conjunto de datos.
9.2 K-Medias
El algoritmo de agrupamiento de k-medias funciona de la siguiente manera:
Primero, el analista tiene que elegir k - el número de clases (o grupos). Luego colocamos aleatoriamente k vectores de características, llamados centroides, en el espacio de características.
Luego calculamos la distancia desde cada ejemplo x a cada centroide usando alguna métrica, como la distancia euclidiana. Luego asignamos el centroide más cercano a cada ejemplo (como si etiquetáramos cada ejemplo con una identificación de centroide como etiqueta). Para cada centroide, calculamos el vector de características promedio de los ejemplos etiquetados con él. Estas características promedio los vectores se convierten en las nuevas ubicaciones de los centroides.
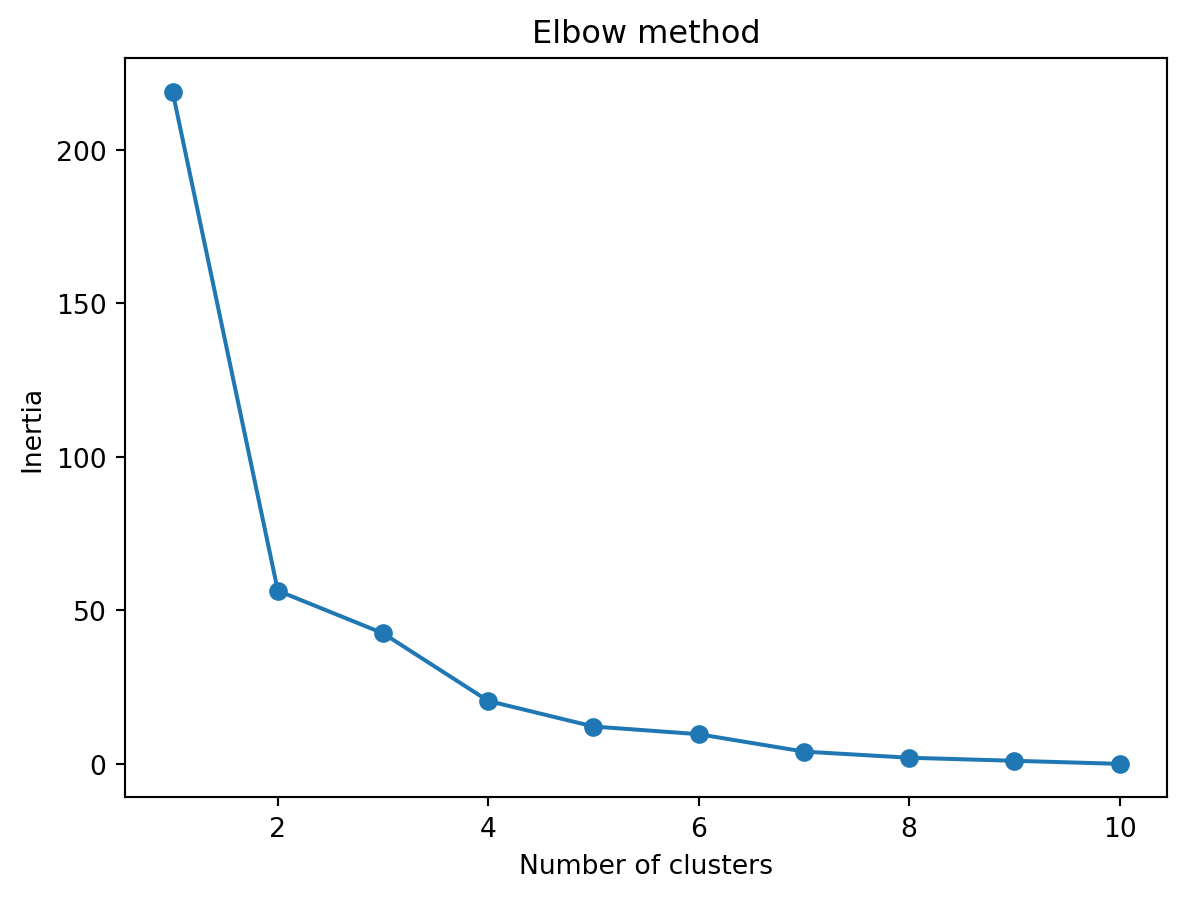
El valor de k, el número de clusters, es un hiperparámetro que los datos deben ajustar. Existen algunas técnicas para seleccionar k. Ninguno de ellos ha demostrado ser óptimo. La mayoría de requieren que el analista haga una “suposición fundamentada” observando algunas métricas o examinando visualmente las asignaciones de grupos. Más adelante en este capítulo, consideraremos una técnica lo que permite elegir un valor razonablemente bueno para k sin mirar los datos y hacer suposiciones.
Método del codo para seleccionar la cantidad de k:
from sklearn.cluster import KMeansdata =list(zip(x, y))inertias = []for i inrange(1,11): kmeans = KMeans(n_clusters=i, n_init="auto") kmeans.fit(data) inertias.append(kmeans.inertia_)plt.plot(range(1,11), inertias, marker='o')plt.title('Elbow method')plt.xlabel('Number of clusters')plt.ylabel('Inertia')plt.show()
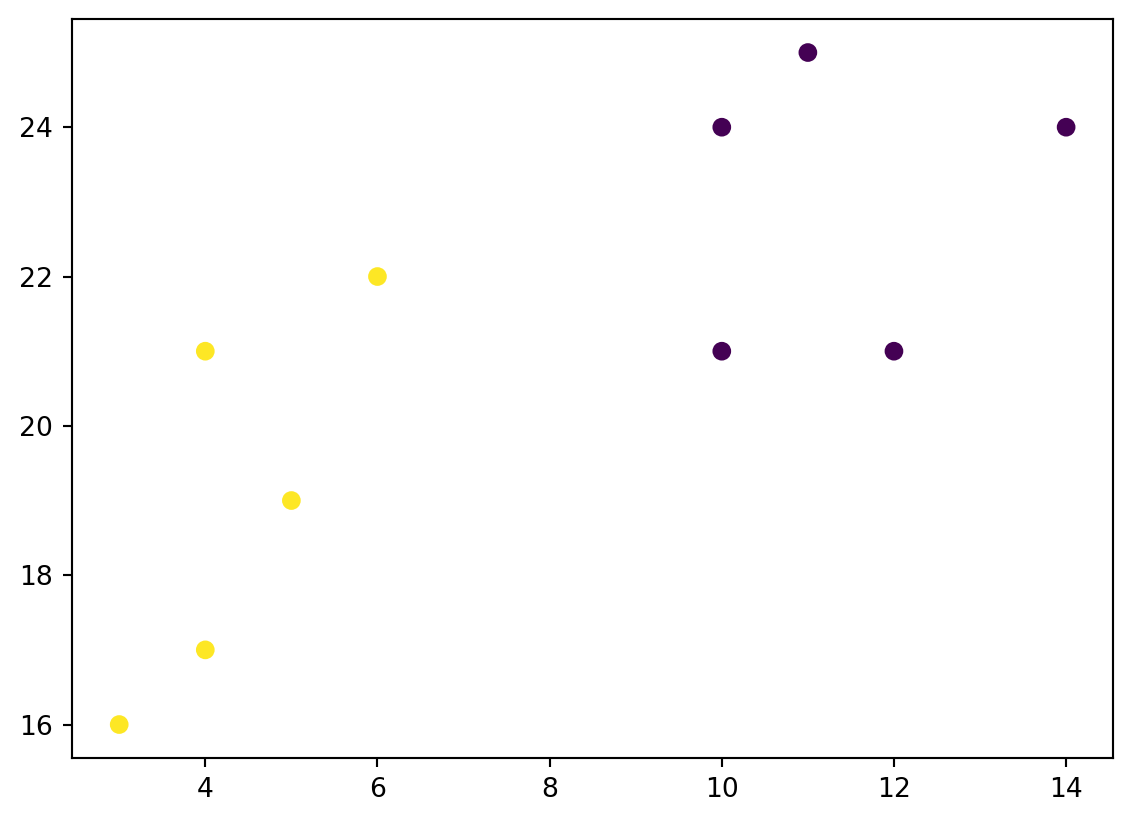
kmeans = KMeans(n_clusters=2, n_init="auto")kmeans.fit(data)plt.scatter(x, y, c=kmeans.labels_)plt.show()
9.3 Reducción de dimensionalidad
9.3.1 Análisis de componentes principales (PCA)
9.3.2 UMAP
UMAP (Uniform Manifold Approximation and Projection) es un algoritmo de aprendizaje de manifolds para la reducción de dimensionalidad, superior a t-SNE por su eficiencia y versatilidad. Desarrollado por Leland McInnes, John Healy y James Melville en 2018, UMAP se fundamenta en el análisis topológico de datos, ofreciendo una metodología robusta para visualizar y analizar datos en alta dimensión.
El algoritmo construye representaciones topológicas de los datos mediante aproximaciones locales del manifold y uniendo estas representaciones en un conjunto simplicial difuso. Minimiza la entropía cruzada entre las representaciones topológicas de los espacios de alta y baja dimensión para lograr una proyección coherente.
Se dará un resumen básico del método, sin embargo se recomienda leer el artículo original de UMAP para una comprensión más profunda.
9.3.3 Análisis topológico de datos y complejos simpliciales
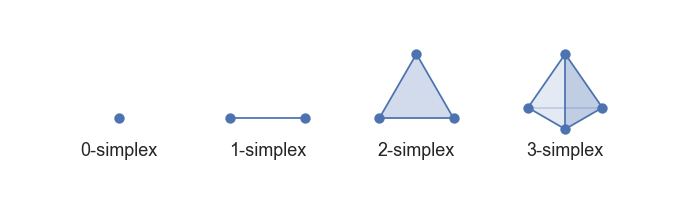
Geometricamente, un \(k\)-simplex es un objeto \(k\)-dimensional que es simplemente la envolutra convexa de \(k+1\) puntos en un espacio \(k\)-dimensional. Un 0-simplex es un vértice, un 1-simplex es una arista, un 2-simplex es un triángulo, un 3-simplex es un tetraedro, etc.
Un complejo simplicial \(K\) es una colección de simplexes que cumple con dos propiedades:
Cada cara de un simplex en \(K\) también está en \(K\).
La intersección de dos simplexes en \(\sigma_{1}, \sigma_{2} \in K\) es una cara de ambos \(\sigma_{1}\) y \(\sigma_{2}\).
9.3.4 Construcción intuitiva de UMAP
Un conjunto de datos es solo una colección finita de puntos en un espacio. En general para entender las características topoloficas, necesitas crear una covertura abierta del espacio. Si los datos están en un espacio métrico, una forma de aproximar esas coverturas abiertas es con bolas abiertas alrededor de cada punto.
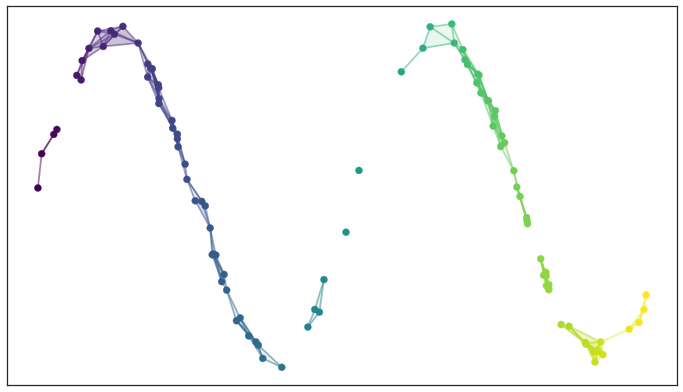
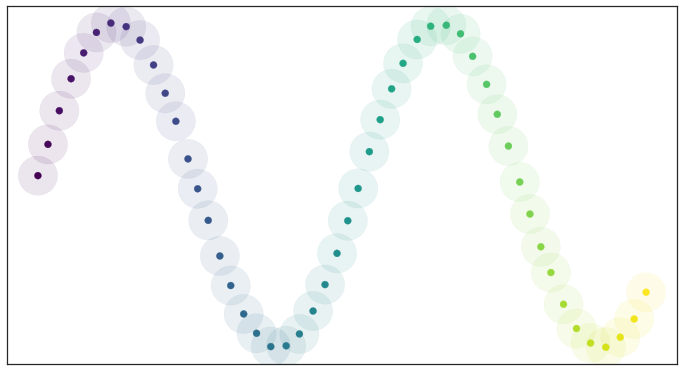
Por ejemplo, suponga que se tiene un conjunto con esta forma:
Si se toma cada punto y se dibuja una bola alrededor de él, se obtiene algo como esto:
Podemos generar un complejo simplicial a través de un complejo Vietoris-Rips. Este complejo se construye tomando cada bola y creando una arista entre cada par de bolas que se superponen. Luego, se crean triángulos entre cada terna de bolas que se superponen, y así sucesivamente.
Esto genera que ahora los datos estén representados a través de un grafo en baja dimensión.
9.3.5 Adaptación del problema a datos reales
Problema #1: Escogencia del radio
La técnica anterior tiene un problema, no sabemos de antemano el radio óptimo de las bolas. Entonces:
Radio es muy pequeno -> No se capturan las relaciones entre los puntos
Radio es muy grande -> Se pierde la estructura local de los datos
Solución: Asumir que los datos son uniformes en la variedad
El problema es que este tipo de supuesto no es real para toda la variedad. El problema es que la noción de distancia varía de punto a punto. En algunos puntos es más largo otros más corto.
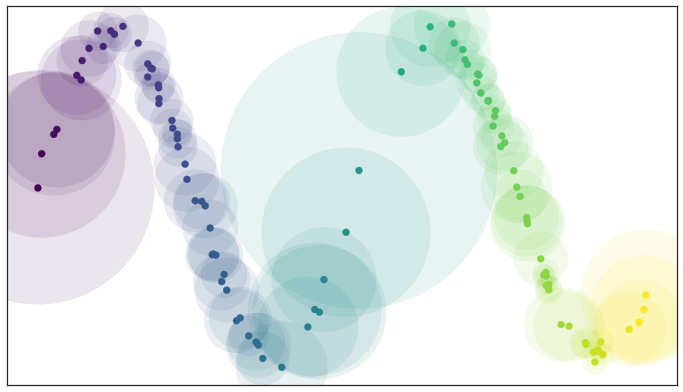
Sin embargo, podemos construir una aproximación de uniformidad local de los puntos usando la geometría Riemaniana. Esto es que la bola alrededor de un punto se extiende hasta los \(k\) vecinos más cercanos. Así que cada punto tendrá su propia función de distancia.
Desde un punto topológico, \(k\) significa qué tanto queremos estimar la métrica Riemaniana localmente. Si \(k\) es pequeño se explicaría features muy locales. Si \(k\) es grande, el features sería más global.
9.3.6 Un beneficio de la geometría Riemaniana
Se puede tener un espacio métrico asociado con cada punto. Es decir, cada punto puede medir distancia de forma significativa de modo que se puede estimar el peso de las aristas del grafo con las distancias que se genera.
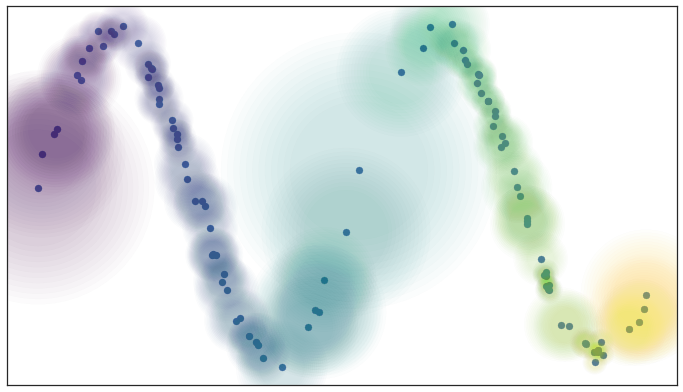
Ahora, pensemos que si en lugar de decir que la covertura fue una un “si” o “no”, fuera un concepto más difuso como un valor de 0 a 1. Entonces, a partir del cierto punto, el valor se vuelve mas cercano a 0 conforme nos alejamos de este.
Problema #2: El manifold podría no estar conectado totalmente.
Es decir, el manifold podría ser simplemente un montón de islas de puntos sin vecinos muy cercanos.
Solución: Usar la conectividad local.
El algoritmo asume que el manifold es localmente conexo. Debido a la maldición de la dimensionalidad, los datos en un espacio de alta dimensión tienen una mayor distancia, pero también pueden ser más similares entre sí. Esto significa que la distancia al primer vecino más cercano puede ser bastante grande, pero la distancia al décimo vecino más cercano suele ser solo ligeramente mayor (relativamente hablando). La restricción de conectividad local asegura que nos centremos en la diferencia de distancia entre los vecinos más cercanos, no en la distancia absoluta (lo que muestra que la diferencia entre vecinos es pequeña).
Problema 3: Incompatibilidad de la métrica local.
Cada punto tiene una métrica local asociada, y desde el punto de vista del punto \(a\), la distancia desde el punto a hasta el punto b puede ser 1.5, pero desde el punto de vista del punto \(b\), la distancia desde el punto b hasta el punto a podría ser solo 0.6.
Basándonos en la intuición del gráfico, se puede considerar que esto es un borde dirigido con diferentes pesos, como se muestra en la siguiente figura:
Combinar los dos bordes inconsistentes con pesos a y b juntos, entonces deberíamos tener un peso combinado \(a+b-a\cdot b\). La forma de pensar esto es que el peso es en realidad la probabilidad de que exista el borde (1-símplex). Entonces, el peso combinado es la probabilidad de que exista al menos un borde.
Si aplicamos este proceso para fusionar todos los conjuntos simpliciales difusos juntos, terminamos con un solo complejo simplicial difuso, que podemos considerar nuevamente como un gráfico ponderado. En términos de cálculo, simplemente aplicamos la fórmula de combinación de pesos de bordes a todo el gráfico (el peso de los no bordes es 0). Al final, obtenemos algo como esto.
Entonces, asumiendo que ahora tenemos una representación topológica difusa de los datos (hablando matemáticamente, capturará la topología del manifold detrás de los datos), ¿cómo lo convertimos en una representación de baja dimensión?
9.3.7 Encontrando una representación de baja dimensión
La representación de baja dimensión debe tener la misma estructura topologica fuzzy de los datos. Tenemos dos problemas acá: 1. Cómo determinar la representación fuzzy en el espacio de baja dimensión y 2. cómo encontrar una buena.
Para 1., básicamente se haraá el mismo proceso pero con un espacio de \(\mathbb{R}^2\) o \(\mathbb{R}^3\).
Con 2., el problema se resuelve calibrando las mismas distancias de la topología difusa en la variedad con respecto a la distancias de la topología en \(\mathbb{R}^{2}\).
Recordando el método de procesamiento de peso anterior, interpretamos el peso como la probabilidad de la existencia de un símplex. Dado que las dos topologías que estamos comparando comparten el mismo 0-símplex, es concebible que estamos comparando dos vectores de probabilidad indexados por el 1-símplex. Suponiendo que estos son todas variables de Bernoulli (el símplex final existe o no, y la probabilidad es un parámetro de la distribución de Bernoulli), la elección correcta aquí es la entropía cruzada.
Para entender el proceso priero definamos algunos conceptos.
Usando los \(k\) vecinos más cercanos para \(x_i\) es el conjunto de puntos \(\{x_{i_{1}}, \dots, x_{i_{k}}\}\) tal que:
Si el conjunto de todos los posibles 1-símplexes entre \(x_i\) y \(x_j\) y la función ponderada hace que \(w_h(x_{i}, x_{j})\) sea el peso de ese simplex en la dimensión alta, y \(w_l(x_i^{l}, x_j^{l})\) en la dimensión baja, entonces la entropía cruzada es:
Desde la perspectiva de los gráficos, minimizar la entropía cruzada se puede considerar como un algoritmo de diseño de gráficos dirigido por fuerza.
El primer ítem, \(w_h(e) \log(w_h(e)/w_l(e))\) proporciona atracción entre los puntos \(e\) cuando hay un peso mayor en el espacio de alta dimensión. Al minimizar este sumando \(w_l(e)\) debe ser lo más grande posible y la distancia entre puntos es lo más pequeña posible.
El segundo sumando, \((1 - w_h(e)) \log((1 - w_h(e))/(1 - w_l(e)))\) proporciona fuerza repulsiva entre los dos segmentos de \(e\) cuando \(w_h(e)\) es pequeño. Al hacer \(w_l(e)\) lo más pequeño posible, se minimiza esta parte.
9.3.8 Ejemplos
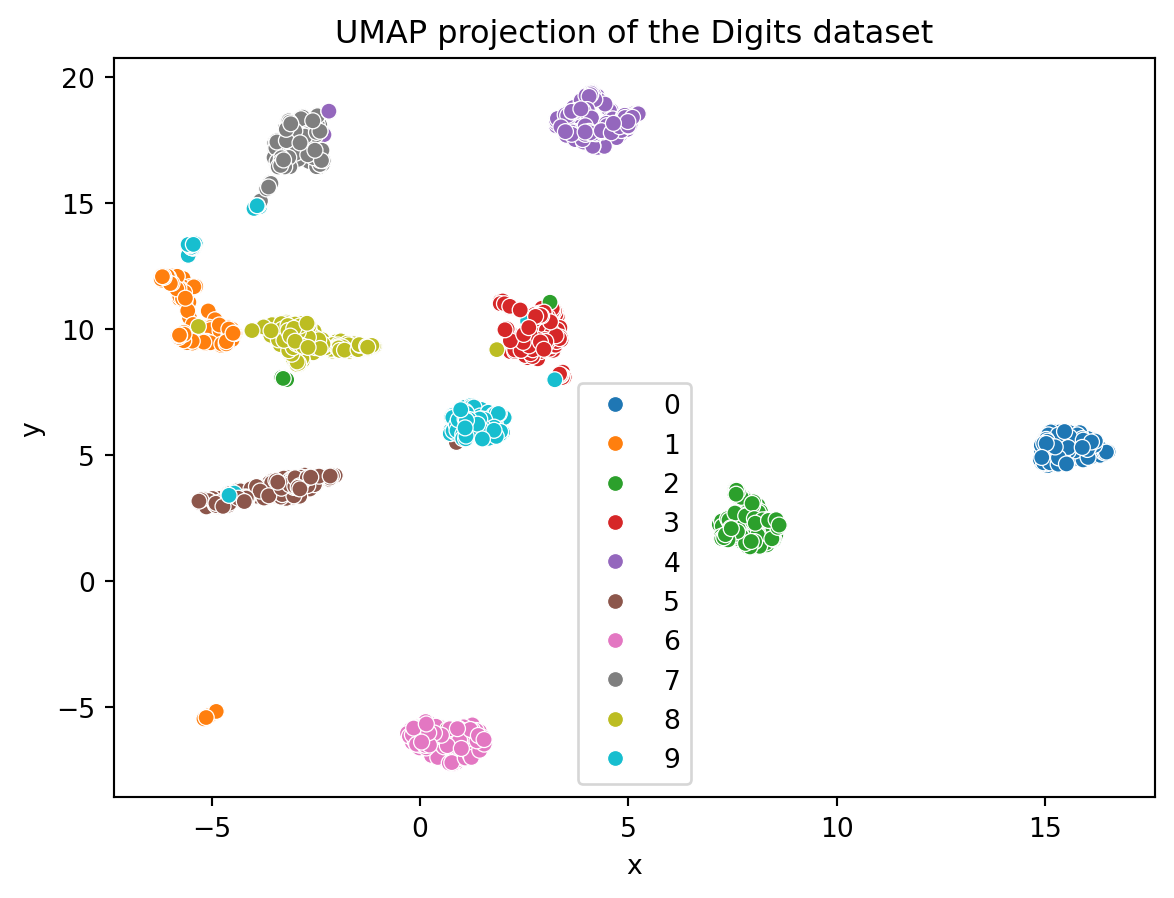
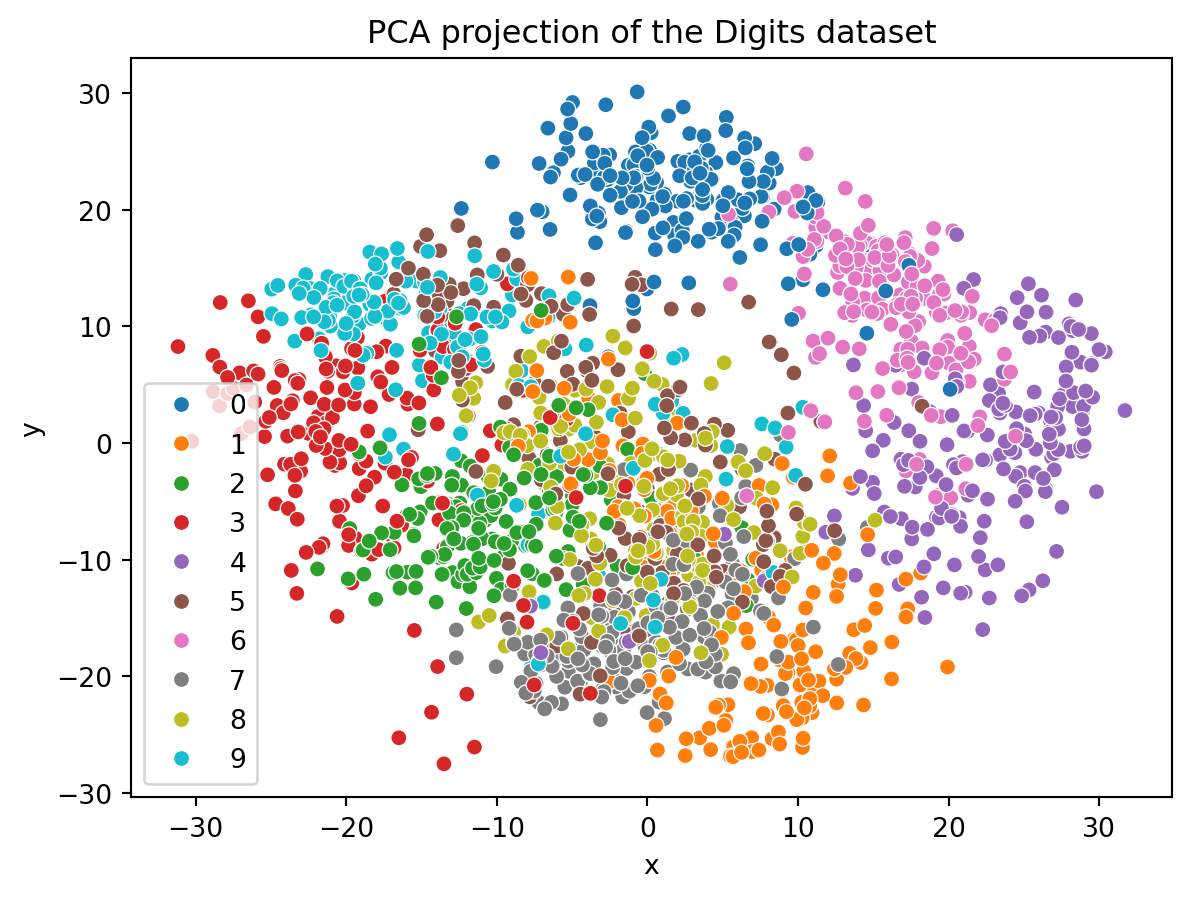
import umapimport seaborn as snsimport matplotlib.pyplot as pltfrom sklearn.datasets import load_digitsimport pandas# Cargar el conjunto de datosdigits = load_digits()data = digits.datatarget = digits.target# Instanciar UMAP y reducir la dimensionalidadreducer = umap.UMAP(random_state=42)data_reduced = reducer.fit_transform(data)data_reduced = pandas.DataFrame(data_reduced, columns=["x", "y"])# Visualizar el resultadosns.scatterplot(data= data_reduced,x ="x", y="y", hue=target, palette='tab10')plt.title('UMAP projection of the Digits dataset')plt.show()# Compare el ressultado con PCAfrom sklearn.decomposition import PCApca = PCA(n_components=2)data_pca = pca.fit_transform(data)data_pca = pandas.DataFrame(data_pca, columns=["x", "y"])sns.scatterplot(data= data_pca,x ="x", y="y", hue=target, palette='tab10')plt.title('PCA projection of the Digits dataset')plt.show()
2024-02-12 14:56:06.076788: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
/usr/local/lib/python3.11/site-packages/umap/umap_.py:1943: UserWarning:
n_jobs value -1 overridden to 1 by setting random_state. Use no seed for parallelism.
OMP: Info #276: omp_set_nested routine deprecated, please use omp_set_max_active_levels instead.
import umap.umap_ as umapfrom sklearn.datasets import load_digitsfrom sklearn.model_selection import train_test_splitfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.metrics import accuracy_scorefrom sklearn.svm import SVC# Cargar el conjunto de datosdigits = load_digits()data = digits.datatarget = digits.target# Dividir el conjunto de datosX_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.25, random_state=42)
# Reducción de dimensionalidad con UMAPumap_reducer = umap.UMAP(random_state=42)X_train_reduced = umap_reducer.fit_transform(X_train)X_test_reduced = umap_reducer.transform(X_test)# Claificación con SVMsvm = SVC()svm.fit(X_train_reduced, y_train)# Predicción y evaluacióny_pred = svm.predict(X_test_reduced)print("Accuracy con UMAP:", accuracy_score(y_test, y_pred))
/usr/local/lib/python3.11/site-packages/umap/umap_.py:1943: UserWarning:
n_jobs value -1 overridden to 1 by setting random_state. Use no seed for parallelism.
Accuracy con UMAP: 0.9666666666666667
# Clasificación con SVMsvm = SVC()svm.fit(X_train, y_train)# Predicción y evaluacióny_pred = svm.predict(X_test)print("Accuracy sin UMAP:", accuracy_score(y_test, y_pred))
Accuracy sin UMAP: 0.9866666666666667
# Reducción de dimensionalidad con PCApca = PCA(n_components=2)X_train_pca = pca.fit_transform(X_train)X_test_pca = pca.transform(X_test)# Clasificación con SVMsvm = SVC()svm.fit(X_train_pca, y_train)# Predicción y evaluacióny_pred = svm.predict(X_test_pca)print("Accuracy con PCA:", accuracy_score(y_test, y_pred))